How to build parallel and isolated browser game agents for Reinforcement Machine Learning
Many Reinforcement Learning tutorials use the OpenAI Gym environment and its supported games to run on different algorithms. But what if you wanted to use Reinforcement Learning for your own environment? Usually you will no longer have ready-built APIs to interact with the environment, the environment itself may be slower than Gym’s games, making it difficult to take the millions of steps for weight updates necessary to train agent models.
Lately I’ve been exploring RL for a Bubble Shooter game - an Adobe Flash based game running in the browser. Previously I would run the game in my primary browser, and use Pynput library to control my computer’s mouse and/or keyboard. This works for a single game instance, but is slow - one step taking 2-5 seconds. So running multiple game instances is necessary to speed up learning, but the original approach of controlling device’s primary mouse or keyboard does not scale that way easily.
What helped to speed up the learning process was to use Selenium+Firefox to run the isolated game instances, allowing for straightforward controls for each instance without blocking the device’s primary controls, and running every game instance and the RL agent in separate processes.
Selenium provides some key functionality necessary for this to work:
- An easy way to take screenshots of DOM elements for the Vision module to use
- An easy way to send mouse/keyboard inputs to a specific DOM element
- Allows running Flash based applications
Game instance isolation with Selenium and Firefox
Selenium Python driver can be installed with pip install selenium.
Firefox will also require a geckodriver package to be available in your $PATH: How to install geckodriver
Flash is abandoned and modern browsers no longer include it. On Ubuntu browser-plugin-freshplayer-pepperflash needs to be installed to get flash running: sudo apt-get install browser-plugin-freshplayer-pepperflash.
In the Selenium’s Firefox webdriver instance Flash can be enabled with a profile preference:
from selenium import webdriver
# ...
profile = webdriver.FirefoxProfile()
profile.set_preference("plugin.state.flash", 2)
driver = webdriver.Firefox(profile)
The webpage with the flash game can be opened with:
driver.get('https://www.kongregate.com/games/Paulussss/bubbles-shooter')
The correct DOM element can be found with:
game_board_element = driver.find_element_by_tag_name('embed')
Mouse movements and clicks are performed using ActionChains mechanism. It’s a convenient wrapper and will wait for actions to complete before returning:
target_x, target_y = (50, 50) # some x, y coordinates
action_chains = webdriver.common.action_chains.ActionChains(driver)
action_chains.move_to_element_with_offset(game_board_element, target_x, target_y)
action_chains.click()
action_chains.perform()
Game board screenshots can be taken with game_board_element.screenshot_as_png.
This will return a Base64 encoded PNG image, which we can turn into an OpenCV compatible Numpy array:
import numpy as np
import cv2
# ...
base64_png = game_board_element.screenshot_as_png
file_bytes = np.asarray(bytearray(base64_png), dtype=np.uint8)
decoded_image = cv2.imdecode(file_bytes, cv2.IMREAD_COLOR)
rect = game_board_element.rect
(x, y, w, h) = (int(rect['x']), int(rect['y']), int(rect['width']), int(rect['height']))
cropped_image = decoded_image[y:y+h, x:x+w]
import namedtuple
Board = namedtuple('Board', ['x', 'y', 'w', 'h', 'screen'])
board = Board(x, y, w, h, cropped_image)
That finds the position of the game board, its dimensions and its contents - all that’s needed for further processing and interaction.
Parallelizing game instances with multiprocessing
Using threads is an option, but because the goal is to run many game instances (24 in my case), I went with Processes instead to make use of all CPU cores.
The distribution is as follows:
- Main Supervisor, responsible for starting the agents and workers, managing queues
- Agent process, responsible for running and training the RL model
- N trainer/player processes, responsible for running Selenium and game instances.
Inter-process communication will be performed through Queue instances, as inspired by Akka’s Actors.
1. Agent worker
from multiprocessing import Process, Queue
class AgentProcess:
def __init__(self, config, my_queue, worker_queues):
self.agent = Agent(config) # create our agent
self.my_queue = my_queue
self.worker_queues = worker_queues
def send_message(self, worker, message):
self.worker_queues[worker].put_nowait(message)
def work(self):
try:
while True:
message = self.my_queue.get(block=True, timeout=60)
if message['command'] == 'act':
self.send_message(message['worker'], self.agent.act(message['state']))
else:
# Add other Agent actions
except queue.Empty:
return False
def agent_worker(config, my_queue, worker_queues):
agent = AgentProcess(config, my_queue, worker_queues)
return agent.work()
The idea is that the Agent process will keep waiting for messages from the Player workers with new states of the game board.
Then it will ask the Agent to make a move, and will respond back to the correct Player worker about which action it should take.
In this case the Agent has one queue to receive messages from all Player workers, but every Player will have their own queues to receive messages from the Agent.
Since processes are isolated, the Agent process will be able to have its own Tensorflow model instance and related resources.
2. Player worker
The player worker is responsible for running the game environment, and just needs to ask the Agent which action it should make at certain points.
class PlayerProcess:
def __init__(self, agent_queue, my_queue, worker_name):
self.agent_queue = agent_queue
self.my_queue = my_queue
self.worker_name = worker_name
def send_to_agent(self, message={}):
message['worker'] = self.worker_name
self.agent_queue.put_nowait(message)
def get_from_agent(self):
return self.my_queue.get(block=True)
def start(self):
self.browser = SeleniumBrowser()
self.browser.setup()
def stop(self):
self.browser.cleanup()
def play(self, episodes, steps):
for e in range(episodes):
state = self.browser.get_game_board()
for step in range(steps):
self.send_to_agent({ 'command': 'act', 'state': state })
action = self.get_from_agent()
self.browser.move_to(action, 400)
def player_worker(config, agent_queue, my_queue, my_name):
player = PlayerProcess(agent_queue, my_queue, my_name)
player.start()
player.play(config['episodes'], config['steps'])
player.stop()
This PlayerProcess is simplified to show the main ideas.
But in English all this does is gets the Selenium instance to get the game board state, asks the Agent to choose an action based upon the state, and asks the Selenium instance to perform the action.
3. Training supervisor
The training supervisor needs to start all of the relevant processes, queues. It also starts training, and releases all resources afterwards.
class Supervisor:
def __init__(self, config, total_players=2):
self.total_players = total_players
self.agent_queue = Queue()
self.worker_queues = [Queue() for _ in range(total_players)]
self.config = config
self.agent = Process(target=agent_worker, args=(config,))
self.workers = [Process(target=player_worker, args=(config, self.agent_queue, self.worker_queues[name]) for name in range(total_players)]
def start(self):
self.agent.start()
for worker in self.workers:
worker.start()
def wait_to_finish(self):
for worker in self.workers:
worker.join()
self.agent.terminate()
And to actually run the supervisor, all player instances and start the playing process:
config = #... - some config
if __name__ == '__main__':
supervisor = Supervisor(config, total_players=10)
supervisor.start()
supervisor.wait_to_finish()
Once executed, this should start a bunch of browsers:
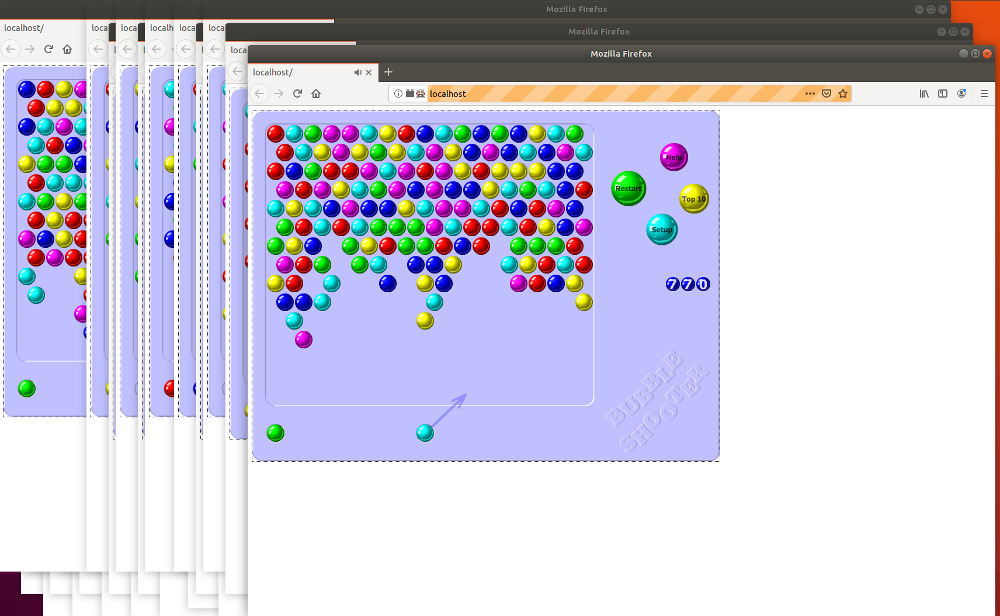
I’m using this approach to run 24 game instances for my Q-learning process for Bubble Shooter. If you’d like to see it in action, you can find it on GitHub.
Subscribe via RSS